 |
Jim Chow, Ben Pfaff, Tal Garfinkel, Mendel Rosenblum
{jchow,blp,talg,mendel}@cs.stanford.edu
Stanford University Department of Computer Science
We present a strategy for reducing the lifetime of data in memory called secure deallocation. With secure deallocation we zero data either at deallocation or within a short, predictable period afterward in general system allocators (e.g. user heap, user stack, kernel heap). This substantially reduces data lifetime with minimal implementation effort, negligible overhead, and without modifying existing applications.
We demonstrate that secure deallocation generally clears data immediately after its last use, and that without such measures, data can remain in memory for days or weeks, even persisting across reboots. We further show that secure deallocation promptly eliminates sensitive data in a variety of important real world applications.
Clearing sensitive data, such as cryptographic keys, promptly after use is a widely accepted practice for developing secure software [23,22]. Unfortunately, this practice is largely unknown in commodity applications such as word processors, web browsers, and web servers that handle most of the world's sensitive data, e.g. passwords, confidential documents.
Consequently, sensitive data is often scattered widely through user and kernel memory and left there for indefinite periods [5]. This makes systems needlessly fragile, increasing the risk of exposing sensitive data when a system is compromised, or of data being accidentally leaked due to programmer error [1] or unexpected feature interactions (e.g. core dumps [15,16,14,13], logging [5]).
We advocate a solution to this based on the observation that data's last use is usually soon before its deallocation. Thus, we can use deallocation as a heuristic for when to automatically zero data.
By zeroing data either at deallocation or within a short predictable period afterward in system allocators (heap, stack, kernel allocators, etc.), we can provide significantly shorter and more predictable data lifetime semantics, without modifying existing applications. We refer to this automatic approach to zeroing as secure deallocation.
We define the concept of a data life cycle to provide a conceptual framework for understanding secure deallocation. Using this framework, we characterize the effectiveness of secure deallocation in a variety of workloads.
We evaluated secure deallocation by modifying all major allocation systems of a Linux system, from compiler stack, to malloc-controlled heap, to dynamic allocation in the kernel, to support secure deallocation. We then measured the effectiveness and performance overheads of this approach through the use of whole-system simulation, application-level dynamic instrumentation, and benchmarks.
Studying data lifetime across a range of server and interactive workloads (e.g. Mozilla, Thunderbird, Apache and sshd), we found that with careful design and implementation, secure deallocation can be accomplished with minimal overhead (roughly 1% for most workloads).
We further show that secure deallocation typically reduces data lifetime to within 1.35 times the minimum possible data lifetime (usually less than a second). In contrast, waiting for data to be overwritten commonly produces a data lifetime 10 to 100 times the minimum and can even stretch to days or weeks. We also provide an in-depth analysis demonstrating the effectiveness of this approach for removing sensitive data across the entire software stack for Apache and Emacs.
We argue that these results provide a compelling case for secure deallocation, demonstrating that it can provide a measurable improvement in system security with negligible overhead, without requiring program source code to be modified or even recompiled.
Our discussion proceeds as follows. In the next section we present the motivation for this work. In section 3 we present our data lifetime metric and empirical results on how long data can persist. In section 4 we present the design principles behind secure deallocation while sections 5, 6, and 7 present our analysis of effectiveness and performance overheads of secure deallocation. In sections 8 and 9 we discuss future and related work. Section 10 offers our conclusions.
The simplest way to gain access to sensitive data is by directly compromising a system. A remote attacker may scan through memory, the file system or swap partition, etc. to recover sensitive data. An attacker with physical access may similarly exploit normal software interfaces [7], or if sufficiently determined, may resort to dedicated hardware devices that can recover data directly from device memory. In the case of magnetic storage, data may even be recoverable long after it has been deleted from the operating system's perspective [9,11].
|
Software bugs that directly leak the contents of memory are common. One recent study of security bugs in Linux and OpenBSD discovered 35 bugs that can be used by unprivileged applications to read sensitive data from kernel memory [6]. Recent JavaScript bugs in Mozilla and Firefox can leak an arbitrary amount of heap data to a malicious website [21]. Many similar bugs undoubtedly exist, but they are discovered and eradicated slowly because they are viewed as less pressing than other classes of bugs (e.g. buffer overflows).
Data can be accidentally leaked through unintended feature interactions. For example, core dumps can leak sensitive data to a lower privilege level and in some cases even to a remote attacker. In Solaris, ftpd would dump core files to a directory accessible via anonymous FTP, leaking passwords left in memory [15]. Similar problems have been reported in other FTP and mail servers [16,14,13]. Systems such as ``Dr. Watson'' in Windows may even ship sensitive application data in core files to a remote vendor. Logs, session histories, and suspend/resume and checkpointing mechanisms exhibit similar problems [7].
Leaks can also be caused by accidental data reuse. Uncleared pages might be reused in a different protection domain, leaking data between processes or virtual machines [12]. At one time, multiple platforms leaked data from uncleared buffers into network packets [1]. The Linux kernel implementation of the ext2 file system, through versions 2.4.29 and 2.6.11.5, leaked up to approximately 4 kB of arbitrary kernel data to disk every time a new directory was created [2].
If data leaks to disk, by paging or one of the mechanisms mentioned above, it can remain there for long periods of time, greatly increasing the risk of exposure. Even data that has been overwritten can be recovered [9]. Leaks to network attached storage run the risk of inadvertently transmitting sensitive data over an unencrypted channel.
As our discussion illustrates, data can be exposed through many avenues. Clearly, reducing these avenues e.g. by fixing leaks and hardening systems, is an important goal. However, we must assume in practice that systems will have leaks, and will be compromised. Thus, it behooves us to reduce or eliminate the amount of sensitive data exposure that occurs when this happens by minimizing the amount of sensitive data in a system at any given time.
Unfortunately, most applications take no steps to minimize the amount of sensitive data in memory.
Common applications that handle most sensitive data were never designed with sensitive data in mind. Examples abound, from personal data in web clients and servers, to medical and financial data in word processors and databases. Often even programs handling data known to be sensitive take no measures to limit the lifetime of this data, e.g. password handling in the Windows login program [5].
Applications are not the only culprits here. Operating systems, libraries and language runtimes are equally culpable. For example, in recent work we traced a password typed into a web form on its journey through a system. We discovered copies in a variety of kernel, window manager, and application buffers, and literally dozens of copies in the user heap. Many of these copies were long lived and erased only as memory was incidentally reused much later [5].
Consequently, even when programmers make a best-effort attempt to minimize data lifetime, their efforts are often flawed or incomplete as the fate of memory is often out of their control. A process has no control over kernel buffers, window manager buffers, and even over application memory in the event that a program crashes.
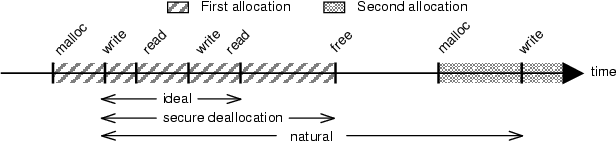
The data life cycle (Figure 1) is a time line of interesting events pertaining to a single location in memory:
Defining data lifetime in this manner provides a framework for reasoning about the effectiveness of zeroing policies. The degree to which the secure deallocation lifetime matches the ideal lifetime gives us a metric for understanding how well secure deallocation approximates an optimal policy.
 |
When memory is reallocated and used for a different purpose, it is not uncommon for the previous contents of the memory to be incompletely overwritten, allowing some data from the previous allocation to survive. We refer to the sections of surviving data as holes. Holes may arise from unused variables or fields, compiler-added padding for stack frame alignment or in structs, or unused portions of large buffers.
For example, it is common for user-level file name handling code to allocate PATH_MAX (at least 256) byte buffers even though they aren't completely used in most situations, and Linux kernel code often allocates an entire 4,096-byte page for a file name. The unused portion of the buffer is a hole. This is important for data lifetime because any data from a previous allocation that is in the hole is not overwritten. Figure 2 illustrates the accumulation of data that can result from these holes.
It might seem that secure deallocation is a superfluous overhead since the job of overwriting sensitive data can simply be handled when the memory is reused. However, in some programs, holes account for the vast majority of all allocated data. Thus, simply waiting for reallocation and overwrite is an unreliable and generally poor way to ensure limited data lifetime. The next section shows an example of this.
On today's systems, we cannot predict how long data will persist. Most data is erased quickly, but our experiments described here show that a significant amount of data may remain in a system for weeks with common workloads. Thus, we cannot depend on normal system activities to place any upper bound on the lifetime of sensitive data. Furthermore, we found that rebooting a computer, even by powering it off and back on, does not necessarily clear its memory.
We wrote Windows and Linux versions of software designed to measure long-term data lifetime and installed it on several systems we and our colleagues use for everyday work. At installation time, the Linux version allocates 64 MB of memory and fills it with 20-byte ``stamps,'' each of which contains a magic number, a serial number, and a checksum. Then, it returns the memory to the system and terminates. A similar program under Windows was ineffective because Windows zeroes freed process pages during idle time. Instead, the Windows version opens a TCP socket on the localhost interface and sends a single 4 MB buffer filled with stamps from one process to another. Windows then copies the buffer into dynamically allocated kernel memory that is not zeroed at a predictable time. Both versions scan all of physical memory once a day and count the remaining valid stamps.
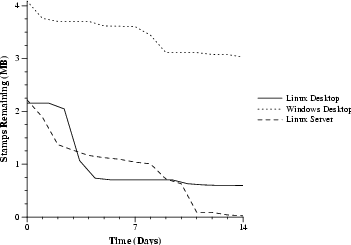
Figure 3 displays results for three machines actively used by us and our colleagues. The machines were Linux and Windows desktops with 1 GB RAM each and a Linux server with 256 MB RAM. Immediately after the fill program terminated, 2 to 4 MB of stamps could be found in physical memory. After 14 days, between 23 KB and 3 MB of the stamps could still be found. If these stamps were instead sensitive data, this could pose a serious information leak.
In the best case, the Linux server, only 23 KB of stamps remained after 14 days. We expected that these remaining stamps would disappear quickly, but in fact, after an additional 14 days, about 7 KB of stamps were still left. A closer look found most data retained over the long term to lie in holes in pages owned by the Linux slab allocator, which divides pages into smaller blocks of equal size for piecemeal use. Most block sizes do not fit evenly into the page size, so leftover space (up to hundreds of bytes worth) follows the final block in a slab, and some blocks also contain data members that are rarely used. This unused space retains data as long as the slab page itself persists--at least as long as any block in the page is in use and ordinarily longer--and slab pages tend to be deallocated in large numbers only under memory pressure. Thus, we expect data that falls into a hole in a slab to persist for a long time on an ordinarily loaded system, explaining our observations.
|
In the course of setting up experiments, we rebooted some machines multiple times and found, to some surprise, that some stamps put into memory before reboot remained. We investigated further and found that a ``soft'' reboot, that is, a reboot that does not turn off the machine's power, does not clear most of RAM on the machines we tested. The effect of a ``hard'' reboot, that is, one that powers off the machine, varied. On some machines, hard reboots cleared all stamps; on others, such as IBM ThinkPad T30 laptops, many were retained even after 30 seconds without power. We conclude that it is a bad idea to assume a reboot will clear memory without knowledge about the specific hardware in use.
Secure deallocation clears data at deallocation or within a short, predictable time afterward. This provides a conservative heuristic for minimizing data lifetime.
Secure deallocation is a heuristic in that we have no idea when a program last uses data. We just leverage the fact that last-time-of-use and time-of-deallocation are often close together (see section 5). This is conservative in that it should not introduce any new bugs into existing programs, and in that we treat all data as sensitive, having no a priori knowledge about how it is used in an application.
This approach is applicable to systems at many levels from OS kernels to language runtimes, and is agnostic to memory management policy, e.g. manual freeing vs. garbage collection. However, the effectiveness of secure deallocation is clearly influenced by the structure and policy of a system in which it is included.
We advocate clearing at every layer of a system where data is deallocated including user applications, the compiler, user libraries, and the OS kernel. Each layer offers its own costs and benefits that must be taken account.
Unfortunately, it can be complex and labor intensive to identify all the places where sensitive data resides and clear it appropriately. We explore an example of modifying a piece of complex, data-handling software (the Linux kernel) to reduce the time that data is held in section 6.
The OS is the final safety net for clearing all of the data possibly missed by, or inaccessible to, user programs. The OS kernel's responsibilities include clearing program pages after a process has died, and clearing buffers used in I/O requests.
Before choosing a layered design, we should demonstrate that it is better than a single-layer design, such as a design that clears only within the user stack and heap management layer.
Clearing only in a lower layer (e.g. in the kernel instead of the user stack/heap) is suboptimal. For example, if we do zeroing only when a process dies, data can live for long periods before being cleared in long running processes. This relates back to the intuition behind the heuristic aspect of secure deallocation.
Clearing only in a higher layer (e.g. user stack/heap instead of kernel) is a more common practice. This is incomplete because it does not deal with state that resides in kernel buffers (see section 6 for detailed examples). Further, it does not provide defense in depth, e.g. if a program crashes at any point while sensitive data is alive, or if the programmer overlooks certain data, responsibility for that data's lifetime passes to the operating system.
This basic rationale applies to other layered software architectures including language runtimes and virtual machine monitors.
The chief reason against a layered design is performance. But as we show in section 7, the cost of zeroing actually turns out to be trivial, contrary to popular belief.
Secure deallocation is subject to a variety of caveats:
Long-lived servers like sshd and Apache are generally written to conscientiously manage their memory, commonly allowing them to run for months on end. When memory leaks do occur in these programs, installations generally have facilities for handling them, such as a cron job that restarts the process periodically.
Region-based allocators [8], for example, serve allocation requests from a large system-allocated pool. Objects from this pool are freed en masse when the whole pool is returned to the system. This extends secure deallocation lifetimes, because the object's use is decoupled from its deallocation.
Circular queues are another common example. A process that buffers input events often does not clear them after processing them from the queue. Queue entries are ``naturally'' overwritten only when enough additional events have arrived to make the queue head travel a full cycle through the queue. If the queue is large relative to the rate at which events arrive, this can take a long time.
These caveats apply only to long-lived processes like Apache or sshd, since short-lived processes will have their pages quickly cleaned by the OS. Furthermore, long-lived processes tend to free memory meticulously, for reasons described above, so the impact of these caveats is generally small in practice.
These challenges also provide unique opportunities. For example, custom allocators designed with secure deallocation can potentially better hide the latency of zeroing, since zeroing can be deferred and batched when large pools are deallocated. Of course, a healthy balance must be met--the longer zeroing is deferred, the less useful it is to do the zeroing at all.
In this section we provide some practical examples of design trade-offs we made in our secure deallocation implementation.
All heap allocated data is zeroed immediately during the call to free. Data is cleared immediately because the latency imposed appears to be negligible in most cases, given the speed of zeroing.
For the stack, we explored two strategies: zeroing activation frames immediately as their function returns and periodically zeroing all data below the stack pointer (all old, currently unused space). The latter strategy amortizes the performance overhead of stack over many calls and returns, although it has the disadvantage of missing ``holes'' in the stack (see section 3.1).
|
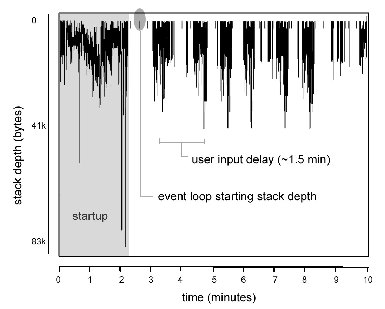
The intuition for periodically zeroing the stack is illustrated by Figure 4, obtained by instrumenting Firefox 1.0. Although applications do make excursions downwards to do initialization or complex processing, many, particularly long-lived ones like network server daemons or GUI programs, spend most of their time high atop the stack, waiting in an event loop for a network/user request.
In the kernel we leveraged our greater knowledge of the semantics of different data structures to selectively clear only memory that may contain sensitive data. We chose this approach because the kernel is performance sensitive, despite the greater effort and implementation complexity required.
Ideally, this approach would provide the same reduction of sensitive data lifetime as we would obtain by clearing everything in the main kernel allocators, perhaps better, as specific data structures such as circular queues are cleared as well. However, as this is not conservative, there is a greater risk that we may have overlooked some potentially sensitive data.
The kernel has two primary responsibilities for zeroing. First, it must clear user space memory which has been deallocated, e.g. by process death or unmapping a private file mapping. Next, it must clear potentially sensitive state residing in I/O buffers e.g. network buffers (e.g. sk_buffs in Linux), tty buffers, IPC buffers.
Due to the range and complexity of zeroing done in the kernel we have deferred most of our discussion to section 6 and further in appendix A.
An unusual aspect of kernel zeroing is the need to clear large areas such as the pages in a terminated process. This requires significant care in order to balance the demand for short and predictable data lifetime against the need for acceptable latency.
To provide predictable data lifetime, we would like to have some sort of deadline scheduling in place, e.g. a guarantee that sensitive pages are zeroed within n seconds of deallocation. We would like n to be as small as possible without imposing unacceptable immediate latency penalties on processes. On the other hand, if n is too large many dirty pages could accumulate, especially under heavy load. This could lead to long and unpredictable pauses while the system stops to zero pages. Intuitively, this is very similar to garbage collection pausing a program to free up memory.
Sometimes proactively zeroing memory can actually improve system responsiveness. Even an unmodified kernel must zero memory before allocating it to a user process, to prevent sensitive data from one protection domain from leaking into another. Often this is done on demand, immediately before pages are needed. Doing this before pages are needed can improve performance for process startup. Zeroing memory can also increase page sharing under some virtual machine monitors [24].
Another important consideration is ensuring that zeroing large pools of memory does not blow out caches. We discuss this issue in section 7.1.
A more complete treatment of zeroing performed by the kernel is provided later in section 6 and appendix A.
Secure deallocation only modifies data with indeterminate content, e.g. freed data on the heap. This should not introduce bugs in correct programs. Some buggy software, however, depends on the value of indeterminate data.
Use of indeterminate data takes two forms. Software may use data before it has been initialized, expecting it to have a constant value. Alternately, software may use data after it has been freed, expecting it to have the same value it had prior to deallocation.
By making the value of indeterminate data consistent, some buggy code will now always break. However, this also changes some non-deterministic ``Heisenbugs'' into deterministic ``Bohr bugs,'' e.g. returning a pointer to a local, stack-allocated variable will always break, instead of just when a signal intervenes between function return and pointer dereference. This can be beneficial as it may bring otherwise hard to find bugs to the surface. Conversely, secure deallocation may eliminate some bugs permanently (e.g. data is always initialized to zero as a programmer assumed).
Implementers of secure deallocation should consider this issue when deciding what value they wish to use for clearing memory. For example, matching the value the existing OS uses for clearing process pages (e.g. zero on Linux x86, 0xDEADBEEF on AIX RS/6000), is a good heuristic for avoiding the introduction of new use-before-initialization bugs.
Using the conceptual framework introduced in section 3, we try to answer these questions using our example implementation of heap clearing and a variety of common workloads.
We created a tool for measuring data lifetime related events in standard user applications. It works by dynamically instrumenting programs to record all accesses to memory: all reads, writes, allocations, and deallocations. Using this information, we can generate precise numbers for ideal, natural, and secure deallocation lifetimes as well as other data properties like holes.
We based our tool on Valgrind [18], an open source debugging and profiling tool for user-level x86-Linux programs. It is particularly well-known as a memory debugger. It also supports a general-purpose binary instrumentation framework that allows it to be customized. With this framework, we can record timestamps for the events illustrated in Figure 1. We can compute various lifetime spans directly from these timestamps.
We performed our experiments on a Linux x86 workstation, selecting applications where data lifetime concerns are especially important, or which lend insight into interesting dynamic allocation behavior:
We omit detailed performance testing for these applications, due to the difficulty of meaningfully characterizing changes to interactive performance. Any performance penalties incurred were imperceptible. Performance of heap zeroing is analyzed in section 7.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The table contains several statistics for each experiment. Run Time is the time for a single run and Allocated is the total amount of heap memory allocated during the run. Written is the amount of allocated memory that was written, and Ideal Lifetime is the ideal lifetime of the written bytes, calculated from first write to last read for every byte written. Written & Freed is the allocated memory that was first written and later deallocated, and Secure Deallocation Lifetime is the data lifetime obtained by an allocator that zeros data at time of free, as the time from first write to deallocation. Finally, Written, Freed, & Overwritten is the allocated bytes that were written and deallocated and later overwritten, with Natural Lifetime the data lifetime obtained with no special effort, as the time from first write to overwrite.
The GUI workloads Mozilla and Thunderbird are visually separated in the table because their data lifetime characteristics differ markedly from the other workloads, as we will discuss further in section 5.5 below.
One thing to note about the binary instrumentation framework Valgrind provides is that it does tend to slow down CPU-bound programs, dilating the absolute numbers for the lifetime of data. However, the relative durations of the ideal, secure deallocation, and natural lifetimes are still valid; and in our workloads, only the Python experiment was CPU-bound.
Our results indicate that simply waiting for applications to overwrite data in the course of their normal execution (i.e. natural lifetime) produces extremely long and unpredictable lifetimes.
To begin, many of our test applications free most of the memory that they allocate, yet never overwrite much of the memory that they free. For example, the Mozilla workload allocates 135 MB of heap, writes 96 MB of it, frees about 94 MB of the data it wrote, yet 14 MB of that freed data is never overwritten.
There are several explanations for this phenomenon. For one, programs occasionally free data at or near the end of their execution. Second, sometimes one phase of execution in a program needs more memory than later phases, so that, once freed, there is no need to reuse memory during the run. Third, allocator fragmentation can artificially prevent memory reuse (see 3.2 for an example).
Our data shows that holes, that is, data that is reallocated but never overwritten, are also important. Many programs allocate much more memory than they use, as shown most extremely in our workloads by Python, which allocated 120 MB more memory than it used, and Apache, which allocated over 11 times the memory it used. This behavior can often result in the lifetime of a block of memory extending long past its time of reallocation.
The natural lifetime of data also varies greatly. In every one of our test cases, the natural lifetime has a higher standard deviation than either the ideal or secure deallocation lifetime. In the xterm experiment, for example, the standard deviation of the natural lifetime was over 20 times that of the secure deallocation lifetime.
Our experiments show that an appreciable percentage of freed heap data persists for the entire lifetime of a program. In our Mozilla experiment, up to 15% of all freed (and written to) data was never overwritten during the course of its execution. Even in programs where this was not an appreciable percentage, non-overwritten data still amounted to several hundred kilobytes or even megabytes of data.
We have noted that relying on overwrite (natural lifetime) to limit the life of heap data is a poor choice, often leaving data in memory long after its last use and providing widely varying lifetimes. In contrast, secure deallocation very consistently clears data almost immediately after its last use, i.e. it very closely approximates ideal lifetime.
Comparing the Written and Written & Freed columns in Table 1, we can see that most programs free most of the data that they use. Comparing Ideal Lifetime to Secure Deallocation Lifetime, we can also see that most do so promptly, within about a second of the end of the ideal lifetime. In the same cases, the variability of the ideal and secure deallocation lifetimes are similar.
Perhaps surprisingly, sluggish performance is not a common issue in secure heap deallocation. Our Python experiment allocated the most heap memory of any of the experiments, 352 MB. If all this memory is freed and zeroed at 600 MB/s, the slowest zeroing rate we observed (see section 7.1), it would take just over half a second, an insignificant penalty for a 46-minute experiment.
Table 1 reveals that GUI programs often delay deallocation longer than other programs, resulting in a much greater secure deallocation lifetime than others.
One reason for this is that GUI programs generally use data for a short period of time while rendering a page of output, and then wait while the user digests the information. During this period of digestion, the GUI program must retain the data it used to render the page in case the window manager decides the application should refresh its contents, or if the user scrolls the page.
Consequently, the in-use period for data is generally quite small, only as much to render the page, but the deallocation period is quite large because data is only deallocated when, e.g., the user moves on to another webpage. Even afterward, the data may be retained because, for user-friendliness, GUI programs often allow users to backtrack, e.g. via a ``back'' button.
Programmers and system designers seem to scoff at the idea of adding secure deallocation to their systems, supposing the overheads to be unacceptable. However, these fears are largely unfounded.
Data that are in cache and properly aligned can be zeroed rapidly, as we will show. In fact, applications seldom allocate and free enough data to make any appreciable change to their running time.
In this section we show that with careful implementation, zeroing can generally be done with nominal overhead. We show experimentally that user level clearing can be achieved with minimal impact on a wide range of applications. And similarly, that kernel clearing can be performed without significantly impacting either CPU or I/O intensive application performance.
All experiments were run on an x86 Linux platform with 1 GB of memory and a 2.40 GHz Pentium 4.
|
All the allocators on our system dole out blocks of data aligned to at least 4-byte boundaries. malloc by default aligns blocks to 8-byte boundaries. Also by default, GCC aligns stack frames on 16-byte boundaries. Given common application allocation patterns, most heap and stack data freed and reallocated are recently used, and thus also likely in cache.
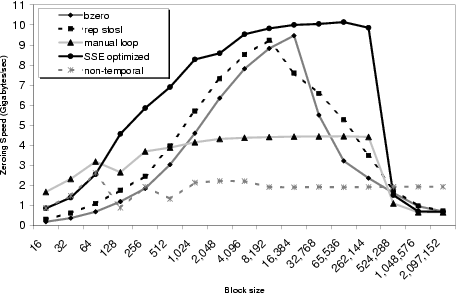
These alignment and cache properties allow even modest machines to zero data at blindingly fast speeds. Figure 5 illustrates this fact for five different methods of zeroing memory:
For small block sizes, fixed overheads dominate. The manual loop is both inlined and very short, and thus fastest. For block sizes larger than the CPU's L2 cache (512 kB on our P4), the approximately 2 GB/s memory bus bandwidth limits speed. At intermediate block sizes, 128-bit SSE stores obtain the fastest results.
Zeroing unused data can potentially pollute the CPU's cache with unwanted cache lines, which is especially a concern for periodic zeroing policies where data is more likely to have disappeared from cache. The non-temporal curve shows that, with non-temporal stores, zeroing performance stays constant at memory bus bandwidth, without degradation as blocks grow larger than the L2 cache size. Moreover, the speed of non-temporal zeroing is high, because cleared but uncached data doesn't have to be brought in from main memory.
When we combine these results with our observations about common application memory behavior, we see that zeroing speeds far outpace the rate at which memory is allocated and freed. Even the worst memory hogs we saw in Table 1 only freed on the order of hundreds of MB of data throughout their entire lifetime, which incurs only a fraction of a second of penalty at the slowest, bus-bandwidth zeroing rate (2 GB/s).
To evaluate the overheads of secure deallocation, we ran test workloads from the SPEC CPU2000 benchmark suite, a standardized CPU benchmarking suite that contains a variety of user programs. By default, the tests contained in the SPEC benchmarks run for a few minutes (on our hardware); it lacks examples of long-lived GUI processes or server processes, which have especially interesting data lifetime issues.
However, we believe that because the SPEC benchmark contains many programs with interesting memory allocation behavior (including Perl, GCC, and an object-oriented database), that the performance characteristics we observe for SPEC apply to these other programs as well. In addition to this, we ran an experiment with the Firefox 1.0 browser. We measured the total time required to startup a browser, load and render a webpage, and then shut-down.
We implemented a zero-on-free heap clearing policy by creating a modified libc that performs zeroing when heap data is deallocated. Because we replaced the entire libc, modifying its internal memory allocator to do the zeroing, we are able to interpose on deallocations performed within the C library itself, in addition to any done by the application. To test heap clearing, we simply point our dynamic linker to this new C library (e.g. via LD_LIBRARY_PATH), and then run our test program.
|
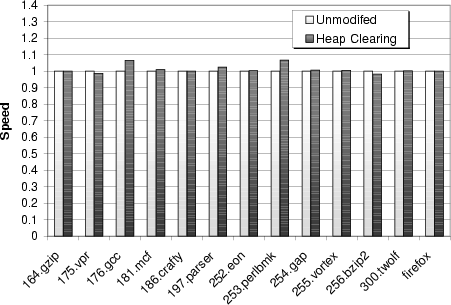
For each program, we performed one run with an unmodified C library, and another with the zero-on-free library. Figure 6 gives the results of this experiment, showing the relative performance of the zero-on-free heap allocator versus an unmodified allocator. Surprisingly, zero-on-free overheads are less than 7% for all tested applications, despite the fact that these applications allocate hundreds or thousands of megabytes of data during their lifetime (as shown in Table 2).
An interesting side-effect of our heap clearing experiment is that we were able to catch a use-after-free bug in one of the SPEC benchmarks, 255.vortex. This program attempted to write a log message to a stdio FILE after it had closed the file. Removing the fclose call fixed the bug, but we had to touch the sources to do this. We don't believe this impacted our performance results.
|
We implemented stack clearing for applications by modifying our OS to periodically zero the free stack space in user processes that have run since the last time we cleared stacks. We do so by writing zero bytes from the user's stack pointer down to the bottom of the lowest page allocated for the stack.
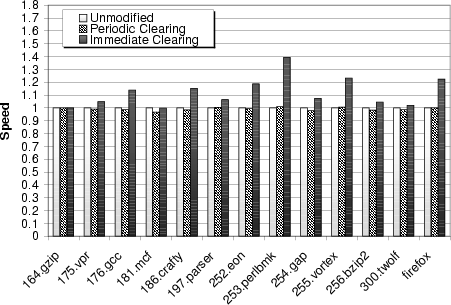
Figure 7 gives the results of running our workload with periodic stack clearing (configured with a period of 5 seconds) plus our other kernel clearing changes. Just like heap clearing, periodic stack clearing had little impact on application performance, with less than a 2% performance increase for all our tests.
For those applications with serious data lifetime concerns, the delay inherent to a periodic approach may not be acceptable. In these cases, we can perform an analog of our heap clearing methodology by clearing stack frames immediately when they are deallocated.
We implemented immediate stack clearing by modifying GCC 3.3.4 to emit a stack frame zeroing loop in every function epilogue. To evaluate the performance impact of this change, we compared the performance of a test suite compiled with an unmodified GCC 3.3.4 against the same test suite compiled with our modified compiler.
Figure 7 gives the results of this experiment. We see that overheads are much higher, generally between 10% and 40%, than for periodic scheduled clearing. Clearly, such overheads are significant, though they may be acceptable for applications where data lifetime is an utmost concern.
We used Linux kernel builds to stress our page zeroing changes. A kernel build starts many processes, each of which modifies many heap, stack, and static data pages not backed by files. The kernel considers all of these polluted and zeros them within five seconds of deallocation.
With the ordinary kernel running, three kernel builds took 184, 182, and 183 seconds, for an average of 183 seconds. With the zeroing kernel, the runs took 188, 184, and 184 seconds, for an average of 185 seconds, approximately a 1% penalty.
The kernel build zeroed over 1.2 million pages (about 4.8 GB) per run. The actual number of polluted pages generated was much larger than that, but many of those pages did not need to be zeroed because they could be entirely overwritten by pages brought into the page cache from disk or by copies of pages created when triggering copy-on-write operations. (As described in section A.2, we prefer to overwrite polluted data whenever possible.)
We evaluated the overhead of zeroing by benchmarking performance on 1 Gbps Ethernet, achieving up to 500 Mbps utilization for large blocks. We found latency, bandwidth, and CPU usage to be indistinguishable between our zeroing kernel and unmodified kernels.
We evaluated the overhead of zeroing network packets using NetPIPE [20], which bounces messages of increasing sizes between processes running on two machines. We configured it to send blocks of data over TCP, in both directions, between a machine running our zeroing kernel and a machine running an unmodified Linux kernel. We then compared its performance against the same test run when both machines were configured with unmodified Linux kernels.
Considering the performance of zeroing depicted in Figure 5, our results are not too surprising. Assuming we zero a buffer sized at the maximum length of an Ethernet frame (1500 bytes), our performance numbers suggest we should be able to zero one second's worth of Gigabit Ethernet traffic in between about 7 ms and 32 ms, depending on the technique used. Such low overheads are well below the normal variance we saw across measurements.
Examining the impact of parallelism is an interesting direction for inquiry. The move to multi-core processors will provide a great deal of additional available parallelism to further diminish the impact of zeroing.
Providing explicit OS support for reducing data lifetime, for example ``ephemeral memory'' that automatically zeroes its contents after a certain time period and thus is secure in the face of bugs, memory leaks, etc., is another area for future investigation.
A wide range of more specialized systems could benefit from secure deallocation. For example, virtual machine monitors and programming language runtimes.
So far we have primarily considered language environments that use explicit deallocation, such as C, but garbage-collected languages pose different problems that may be worthy of additional attention. Mark-and-sweep garbage collectors, for example, prolong data lifetime at least until the next GC, whereas reference-counting garbage collectors may be able to reduce data lifetime below that of secure deallocation.
We explored data lifetime related threats and the importance of proactively addressing data lifetime at every layer of the software stack in a short position paper [7].
The impetus for this and previous work stemmed from several sources.
Our first interest was in understanding the security of our own system as well as addressing vulnerabilities observed in other systems due to accidental information leaks, e.g. via core dumps [15,16,14,13] and programmer error [1].
A variety of previous work has addressed specific symptoms of the data lifetime problem (e.g. leaks) but to the best of our knowledge none has offered a general approach to reducing the presence of sensitive data in memory. Scrash [4] deals specifically with the core dump problem. It infers which data in a system is sensitive based on programmer annotations to allow for crash dumps that can be shipped to the application developer without revealing users' sensitive data.
Previous concern about sensitive data has addressed keeping it off of persistent storage, e.g. Provos's work on encrypted swap [19] and work by Blaze on encrypted file systems [3]. Steps such as these can greatly reduce the impact of sensitive data that has leaked to persistent storage.
The importance of keeping sensitive data off of storage has been emphasized in work by Gutmann [9], who showed the difficulty of removing all remnants of sensitive data once written to disk.
Developers of cryptographic software have long been aware of the need for measures to reduce the lifetime of cryptographic keys and passwords in memory. Good discussions are given by Gutmann [10] and Viega [22].
To address this issue, we argue that the strategy of secure deallocation, zeroing data at deallocation or within a short, predictable period afterward, should become a standard part of most systems.
We demonstrated the speed and effectiveness of secure deallocation in real systems by modifying all major allocation systems of a Linux system, from compiler stack, to malloc-controlled heap, to dynamic allocation in the kernel, to support secure deallocation.
We described the data life cycle, a conceptual framework for understanding data lifetime, and applied it to analyzing the effectiveness of secure deallocation.
We further described techniques for measuring effectiveness and performance overheads of this approach using whole-system simulation, application-level dynamic instrumentation, and system and network benchmarks.
We showed that secure deallocation reduces typical data lifetime to 1.35 times the minimum possible data lifetime. In contrast, we showed that waiting for data to be overwritten often produces data lifetime 10 to 100 times longer than the minimum, and that on normal desktop systems it is not unusual to find data from dead processes that is days or weeks old.
We argue that these results provide a compelling case for secure deallocation, demonstrating that it can provide a measurable improvement in system security with negligible overhead, while requiring no programmer intervention and supporting legacy applications.
This work was supported in part by the National Science Foundation under Grant No. 0121481 and a Stanford Graduate Fellowship.
Section 6.2 described kernel mechanisms for labeling sensitive data. Once these mechanisms are available, we need a policy to distinguish sensitive data from other data. The policy for our prototype implementation was based on a few rules of thumb. First, we considered all user input, such as keyboard and mouse data, all network traffic, and all user process data, to be sensitive.
However, we consider data or metadata read from or written to a file system not sensitive, because its data lifetime is already extended indefinitely simply because it has been written to disk [9]. (For simplicity of prototyping, we ignore the possibility of encrypted, network, in-memory, or removable media file systems, as well as temporary files.) Thus, because pages in shared file mappings (e.g. code, read-only data) are read from disk, they are not considered sensitive even though they belong to user processes. On the other hand, anonymous pages (e.g. stack, heap) are not file system data and therefore deemed sensitive.
We decided that the location of sensitive data is not itself sensitive. Therefore, pointers in kernel data structures are never considered sensitive. Neither are page tables, scheduling data, process ids, etc.
Section 6.2 described the division of kernel allocators into pools and the use of a zeroing daemon to delay zeroing. However, the kernel can sometimes avoid doing extra work, or clear polluted pages more quickly, by using advice about the intended use of the page provided by the allocator's caller:
We applied changes similar to those made to the page allocator to the slab allocator as well. Slabs do not have a convenient place to store a per-block ``polluted'' bit, so the slab allocator instead requires the caller to specify at time of free whether the object is polluted.
Without secure deallocation, allocating or freeing a buffer costs about the same amount of time regardless of the buffer's size. This encourages the common practice of allocating a large, fixed-size buffer for temporary use, even if only a little space is usually needed. With secure deallocation, on the other hand, the cost of freeing a buffer increases linearly with the buffer's size. Therefore, a useful optimization is to clear only that part of a buffer that was actually used.
We implemented such an optimization in the Linux network stack. The stack uses the slab allocator to allocate packet data, so we could use the slab allocator's pollution mechanism to clear network packets. However, the blocks allocated for packets are often much larger than the actual packet content, e.g. packets are often less than 100 bytes long, but many network drivers put each packet into 2 KB buffer. We improved performance by zeroing only packet data, not other unused bytes.
Filename buffers are another place that this class of optimization would be useful. Kernel code often allocates an entire 4 KB page to hold a filename, but usually only a few bytes are used. We have not implemented this optimization.
As already discussed in section 4.3, circular queues can extend data lifetime of their events, if new events are not added rapidly enough to replace those that have been removed in a reasonable amount of time. We identified several examples of such queues in the kernel, including ``flip buffers'' and tty buffers used for keyboard and serial port input, pseudoterminal buffers used by terminal emulators, and the entropy batch processing queue used by the Linux pseudo-random number generator. In each case, we fixed the problem by clearing events held in the queue at their time of removal.